 Index
> Main > (stupid ??) alignment question ??
Index
> Main > (stupid ??) alignment question ?? |
| Author |
|


|
revolution 16 Jan 2026, 13:37
Fword/pword/tword have no "natural" alignment.
I see tword is often aligned to 16, like a dqword. x86 allows all alignments (and mis-alignments) anyway, so they can be placed anywhere. Some CPUs can utilise the cache line to swizzle the bytes into place with no penalty. So on those CPUs 3 twords could be placed into each 32-byte cache line. Try them in various configurations and see how much difference can be noticed. |
|||
|
|
Jessé 16 Jan 2026, 17:44
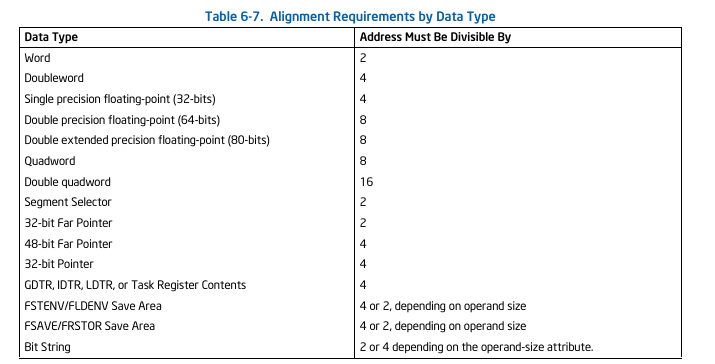
This is actually a very good question. Alignment is related to performance over data access, and, depending on implementation, can even raise exception #AC (FLAGS.AC=1 and cr0.AM=1).
I found something on Intel's Intel 64 and IA32 manual as attached.
|
||||||||||
|
||||||||||
|
revolution 16 Jan 2026, 18:27
Which OSes set the AC flag? I know that Windows and Linux don't. What does the old x86 MacOS do?
But there is a situation where alignment is mandatory, even without the AC flag set. FXSAVE: The destination operand contains the first byte of the memory image, and it must be aligned on a 16-byte boundary. |
|||
|
|
AsmGuru62 17 Jan 2026, 00:19
It will be curious to write some code where TBYTE would be aligned and mis-aligned.
Then measure the time of millions of loads and stores into these fields. I wonder what will be faster, or maybe, inconclusive? |
|||
|
|
revolution 17 Jan 2026, 04:32
When a storage element crosses a cache line that can sometimes show a noticeable drop in performance. Mis-alignment within a cache line might not show any difference.
Try it. |
|||
|
|
revolution 17 Jan 2026, 17:13
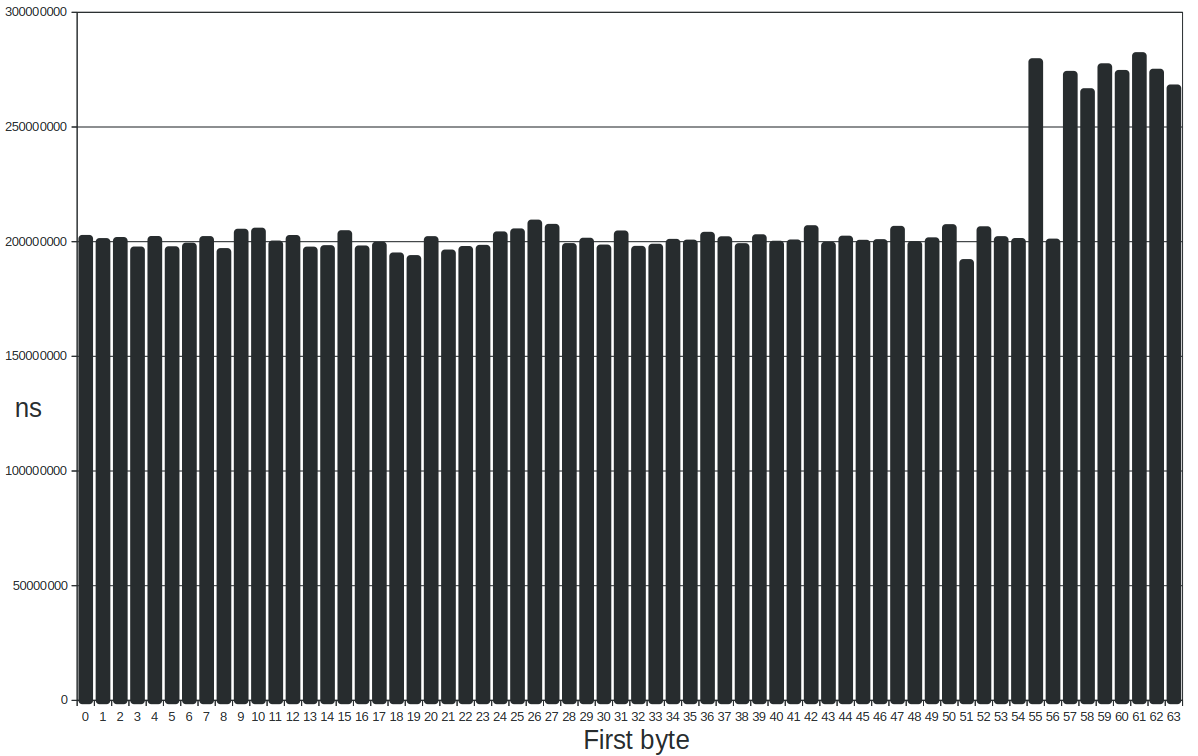
revolution wrote: Try it. Code: format elf64 executable at 1 shl 16 CACHE_LINE_SIZE = 64 TWORD_LOOPS = 1 shl 28 SYS64_write = 1 SYS64_clock_gettime = 228 SYS64_exit_group = 231 CLOCK_PROCESS_CPUTIME_ID= 2 segment executable entry $ ; get the OS to switch the CPU out of low power mode mov eax,CACHE_LINE_SIZE mov ecx,TWORD_LOOPS mov esi,0 call read_twords ; the main loop mov ebp,CACHE_LINE_SIZE .loop: mov eax,SYS64_clock_gettime mov edi,CLOCK_PROCESS_CPUTIME_ID lea rsi,[timespec1] syscall mov eax,CACHE_LINE_SIZE mov ecx,TWORD_LOOPS lea esi,[ebp - 1] call read_twords mov eax,SYS64_clock_gettime mov edi,CLOCK_PROCESS_CPUTIME_ID lea rsi,[timespec2] syscall lea eax,[ebp - 1] call print_decimal mov al,' ' call print_char mov rcx,[timespec1] imul rcx,1000000000 add rcx,[timespec1+8] mov rax,[timespec2] imul rax,1000000000 add rax,[timespec2+8] sub rax,rcx call print_decimal mov al,0xa call print_char sub ebp,1 jnz .loop mov eax,SYS64_exit_group syscall read_twords: ; rax = stride ; rcx = count ; rsi = offset lea rsi,[test_data+rsi] fninit .loop: sub rcx,1 fld tword[rsi] fld tword[rsi+rax] fucompp jnz .loop ret print_decimal: ; rax = value sub rsp,32 mov ecx,10 mov rsi,rsp .loop: xor edx,edx div rcx sub rsi,1 add dl,'0' mov [rsi],dl test rax,rax jnz .loop mov edi,1 mov rdx,rsp sub rdx,rsi mov eax,SYS64_write syscall add rsp,32 ret print_char: ; al = char push rax mov edi,1 mov rsi,rsp mov rdx,1 mov eax,SYS64_write syscall pop rax ret segment readable writeable align 64 test_data db 64 * 3 dup (0xc0) ; make some valid tword floats align 8 timespec1 rq 2 timespec2 rq 2 Code: ~ fasm tword-alignment.asm && ./tword-alignment flat assembler version 1.73.31 (16384 kilobytes memory) 3 passes, 704 bytes. 63 274265389 62 274554841 61 275768167 60 276006914 59 270888481 58 272654384 57 272630350 56 207724707 55 279166600 54 208209127 53 205075196 52 206313466 <...> 0 207314691 Random alignments within a cache line never caused a timing difference. Only when crossing a cache line there is ~35% penalty. And it only slowed when the cache line was crossed by the one of the two separate parts of the tword. Anyhow, that is on this system, with this specific code, on this specific OS, as reported by the Linux SYS64_clock_gettime syscall. Other systems, other codes, other OSes, other syscalls, will probably give entirely different results. |
|||
|
|
AsmGuru62 17 Jan 2026, 17:57
Nice research!
|
|||
|
|
revolution 18 Jan 2026, 08:15
A bit of visualisation never hurts.
|
||||||||||
|
||||||||||
|
Jessé 18 Jan 2026, 15:20
I did a test under a benchmark idea that I've posted here in another thread, and results are quite negligible. The average is the same, although TSC run length (as I called it there) is always longer on unaligned access.
The test benchmark code replaced in the 'test area': Code:
; **********************************
; *** Start Benchmark code ***
finit
fldz
fldz
fstp [align_tw]
fstp [unalign_tw]
lfence
rdtsc
push rdx
push rax
; ### Tested code goes here ###
@@@ fld [unalign_tw]
fld1
faddp
fstp [unalign_tw]
; ### End tested code ###
dec r12
jnz @@b
@@ mfence
rdtsc
pop rbp
pop rcx
; *** End Benchmark code ***
; **********************************
|
|||
|
|
revolution 18 Jan 2026, 16:14
What is the alignment of unalign_tw? It (55 or 57-63) mod 64?
|
|||
|
< Last Thread | Next Thread > |
Forum Rules:
|