 Index
> High Level Languages > understanding jpg decompression
Index
> High Level Languages > understanding jpg decompressionGoto page 1, 2 Next |
| Author |
|


|
vivik 04 May 2018, 19:27
Here is the simplest demonstration of it: https://www.youtube.com/watch?v=Q2aEzeMDHMA
I want to understand the code that is used in libjpeg-turbo for decompressing jpg, specifically the code for inverse discrete cosine transform. There are multiple versions of this code, but I found "float" version to be the simplest: https://github.com/libjpeg-turbo/libjpeg-turbo/blob/master/jidctflt.c Quote: * This implementation is based on Arai, Agui, and Nakajima's algorithm for I guess I need to find either that Arai, Agui, and Nakajima's paper, or that Pennebaker & Mitchell book somewhere to understand that code. Other versions are "slow integer" (jidctint.c simd/jidctint-sse2.asm) and "fast integer" (jfdctfst.c simd/jidctfst-sse2.asm). I'd like to understand all of them. |
|||
|
|
donn 04 May 2018, 20:12
I'm less familiar with DCT, but I think it's similar to the Discrete Fourier Transform (and its inverse). You can represent a signal (such as sound) in the time domain, or spatially if you are dealing with a single two-dimensional image. The Fourier Transform or DCT I think, provides a means to represent that signal in terms of frequencies (the concept of frequency content).
Frequency, by its nature, involves repetitions, so compression can take advantage of these 'redundancies.' The transform involves coefficients which are these building blocks which can be 'decompressed' back to the spatial or time domain (decompressing a JPEG). Fourier thought you could break any signal (sequence of numbers) down into a sum of sines, which some mathematicians thought was impossible. Where the DCT uses cosines (I think in this same way), DFT uses sines and cosines, or analogous complex numbers using Euler's identities. I have H. Joseph Weaver's "Applications of Discrete and Continuous Fourier Analysis" and it's on my to-do to implement a Cooley-Tukey FFT down the road. There are online calculators for some of this stuff, so if you feed in a series of numbers, you can verify the output. I've got Discrete Convolution/Faltung down so far (verified here), but this frequency stuff is very interesting. Mathworks DCT link, showing the principal functions and descriptions of the terms. |
|||
|
|
pabloreda 04 May 2018, 23:40
I code in r4 a jpeg decompress, if you can read a forth like lang, this is the code
https://github.com/phreda4/reda4/blob/master/r4/Lib/loadjpg.txt I use fixed point , the code in this file decompress a file for test and can be use like library. Is a translation of a c code. |
|||
|
|
donn 05 May 2018, 00:28
Wow, r4 is very mature, seems like it has many capabilities.
So the jpeg lib can leverage r4asm to generate fasm-style asm? |
|||
|
|
vivik 05 May 2018, 05:33
@donn
I know the main principle of compression, I need to understand the actual algorithm used in libjpeg. Why this one is used? Why this one is fastest? What are alternatives? How those numbers (0.707106781 0.382683433 1.414213562) are computed? @pabloreda I can't read that, unfortunately. Looks like algorithm is slightly different. |
|||
|
|
Siekmanski 05 May 2018, 06:58
sin( PI / 360 * 90 ) = 0.707106781
sin( PI / 360 * 45 ) = 0.382683433 sqrt(2.0) = 1.414213562 |
|||
|
|
vivik 05 May 2018, 07:29
wow
|
|||
|
|
Siekmanski 05 May 2018, 08:56
If you don't want to use sqrt , you can calculate sqrt(2) as,
sin( PI / 360 * 90 ) * 2 = 1.414213562 |
|||
|
|
vivik 05 May 2018, 12:30
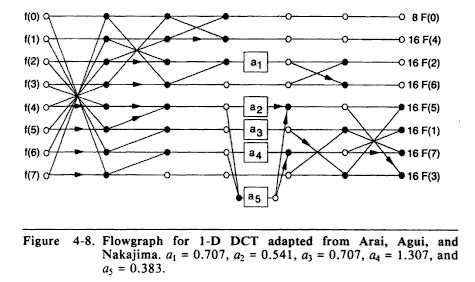
I found this "flowgraph" here:
https://github.com/prtsh/aan_dct https://web.archive.org/web/20100613221721/http://www.ece.ucdavis.edu/cerl/ReliableJPEG/Cung/dct.html https://books.google.com/books?id=AepB_PZ_WMkC&pg=PA52&lpg=PA52&ots=USEOcx5SqG&focus=viewport&dq=Pennebaker+%26+Mitchell+figure+4-8 If you go from left to right, it's "DCT", compression. If you go from right to left, it's decompression. I don't understand what those black dots, white dots and arrows mean. a1 = 0.707 a2 = 0.541 a3 = 0.707 //same as a1 a4 = 1.307 a5 = 0.383
Last edited by vivik on 15 May 2018, 17:02; edited 4 times in total |
|||||||||||||||||||
|
|||||||||||||||||||

|
vivik 05 May 2018, 13:03
So, about different dct algorithms:
[1] and [2] mention Arai-Agui-Nakajima (AAN) algorithm, Loeffler-Ligtenberg-Moschytz (LLM), and Feig and Winograd algorithm. MPEG [1] [2] uses incompatible with jpeg implementation of dct, which is fast but less accurate. [2] describes dct that is as fast as MPEG decompression [3] [4] [5] mention dct that doesn't need any multiplication whatsoever, it uses binary shifts only. I guess this is incompatible with jpg? [1] http://media.taricorp.net/fast_dct.pdf Using Streaming SIMD Extensions in a Fast DCT Algorithm for MPEG Encoding [2] https://www.cs.cmu.edu/~barbic/cs-740/ap922.pdf A Fast Precise Implementation of 8x8 Discrete Cosine Transform Using the Streaming SIMD Extensions and MMX™ Instructions [3] https://en.wikipedia.org/wiki/JPEG_XR "The DCT, the frequency transformation used by JPEG, is slightly lossy because of roundoff error. JPEG XR uses a type of integer transform employing a lifting scheme.[22] The required transform, called the Photo Core Transform (PCT), resembles a 4 × 4 DCT but is lossless (exactly invertible). In fact, it is a particular realization of a larger family of binary-friendly multiplier-less transforms called the binDCT." [4] http://www.sfu.ca/~jiel/bindct.html [5] https://www.vcodex.com/h264avc-4x4-transform-and-quantization/ "This approximation is chosen to minimise the complexity of implementing the transform (multiplication by Cf requires only additions and binary shifts) whilst maintaining good compression performance." |
|||
|
|
vivik 05 May 2018, 13:13
This binary dct is very intriguing. Can you use it with jpg, or maybe jpg-like format? Decompression speed is just as important for me as compression ratio.
Hm, this paper answers this question: http://thanglong.ece.jhu.edu/Tran/Pub/binDCT-VLSI.pdf Same speed, mostly same quality. Can save electricity with proper hardware support. |
|||
|
|
donn 09 May 2018, 20:34
Hi, on the DCT side, I looked into the Matlab equations more and was able to compute and verify some results. Have to catch a train in a couple mins, so this is a bit rushed. I can elaborate points later if needed.
You can start breaking the two dimensional equations down by zeroing out some components and increasing the input size incrementally. I didn't find many online 2D calculators to verify results with, but did find a 1D calculator as one of the first search engine results. I took a few simple input examples, such as: {(3,0),(4,0)} or even {(3,0),(0,0)} each with rowCount and columnCount of 2. In the transform result matrix at index x,y (each base-0), you would multiply an input (such as one of the 3's above at coords 0,0) by cos((PI(2*rowIndex+1)*x)/(2*rowCount)) * cos((PI(2*columnIndex+1)*x)/(2*columnCount)) You then add each of the other input values, with the x,y values constant (since they are only going into this one destination slot in the result matrix. Once you have the sums, you multiply by two other scalars, one for the destination x coordinate, the other for the destination matrix y coordinate. The value for each is calculated as: When the destination x or y is 0, the scalar value is 1/(sqrt(rowCount)) (replacing rowCount with colCount when computing the y equivalent). When the destination index is not 0, the value is similar, but 1/(sqrt(2/rowCount)). So then you just multiply these, the sum, and these two scalar values. In the case above where you rowcount and colCount are both 2, the two values would be approximately 0.707106781186547 and 0.707106781186547 at index 0,0. The inverse transform works on the matrix that was computed to retrive the original using a pretty similar method, but re-arranging when the scalars are multiplied. So for the inputs used above (the first one), dct matrix result should be ((3.5,3.5),(-0.5,-0.5)) Gotta catch this train. r4's fasm output may have some readable asm of the dct, as mentioned earlier. |
|||
|
|
alexfru 10 May 2018, 04:25
vivik wrote: If you go from left to right, it's "DCT", compression. If you go from right to left, it's decompression. I don't understand what those black dots, white dots and arrows mean. https://en.wikipedia.org/wiki/Butterfly_diagram |
|||
|
|
vivik 14 May 2018, 10:30
Found yet another variant of dct. Unfortunately, it's behind the paywall.
https://jpeg.org/jpegxs/ >with very low latency and very low complexity. https://arxiv.org/abs/1606.07414 >Multiplierless 16-point DCT Approximation for Low-complexity Image and Video Coding >requiring only 44 additions---the lowest arithmetic cost in literature. https://www.dpreview.com/news/7572625808/the-new-jpeg-xs-image-format-was-built-for-streaming-4k-and-vr-content >The new JPEG XS image format was built for streaming 4K and VR content >What’s interesting is that JPEG isn’t trying to shrink the file size with JPEG XS. In fact, quite the opposite. Whereas the JPEG standard has a compression ratio of about 10:1, JPEG XS comes out to a 6:1 ratio. |
|||
|
|
vivik 15 May 2018, 14:30
I don't understand anything in that butterfly diagram...
here is code for forward dct, from jfdctflt.c Code: tmp0 = dataptr[0] + dataptr[7]; tmp7 = dataptr[0] - dataptr[7]; tmp1 = dataptr[1] + dataptr[6]; tmp6 = dataptr[1] - dataptr[6]; tmp2 = dataptr[2] + dataptr[5]; tmp5 = dataptr[2] - dataptr[5]; tmp3 = dataptr[3] + dataptr[4]; tmp4 = dataptr[3] - dataptr[4]; /* Even part */ tmp10 = tmp0 + tmp3; /* phase 2 */ tmp13 = tmp0 - tmp3; tmp11 = tmp1 + tmp2; tmp12 = tmp1 - tmp2; dataptr[0] = tmp10 + tmp11; /* phase 3 */ dataptr[4] = tmp10 - tmp11; z1 = (tmp12 + tmp13) * 0.707106781; /* c4 */ dataptr[2] = tmp13 + z1; /* phase 5 */ dataptr[6] = tmp13 - z1; /* Odd part */ tmp10 = tmp4 + tmp5; /* phase 2 */ tmp11 = tmp5 + tmp6; tmp12 = tmp6 + tmp7; /* The rotator is modified from fig 4-8 to avoid extra negations. */ z5 = (tmp10 - tmp12) * 0.382683433; /* c6 */ z2 = 0.541196100 * tmp10 + z5; /* c2-c6 */ z4 = 1.306562965 * tmp12 + z5; /* c2+c6 */ z3 = tmp11 * 0.707106781; /* c4 */ z11 = tmp7 + z3; /* phase 5 */ z13 = tmp7 - z3; dataptr[5] = z13 + z2; /* phase 6 */ dataptr[3] = z13 - z2; dataptr[1] = z11 + z4; dataptr[7] = z11 - z4; here is inverse dct, from jidctflt.c Code: /* Even part */ tmp0 = inptr[0]; tmp1 = inptr[2]; tmp2 = inptr[4]; tmp3 = inptr[6]; tmp10 = tmp0 + tmp2; /* phase 3 */ tmp11 = tmp0 - tmp2; tmp13 = tmp1 + tmp3; /* phases 5-3 */ tmp12 = (tmp1 - tmp3) * 1.414213562 - tmp13; /* 2*c4 */ tmp0 = tmp10 + tmp13; /* phase 2 */ tmp3 = tmp10 - tmp13; tmp1 = tmp11 + tmp12; tmp2 = tmp11 - tmp12; /* Odd part */ tmp4 = inptr[1]; tmp5 = inptr[3]; tmp6 = inptr[5]; tmp7 = inptr[7]; z13 = tmp6 + tmp5; /* phase 6 */ z10 = tmp6 - tmp5; z11 = tmp4 + tmp7; z12 = tmp4 - tmp7; tmp7 = z11 + z13; /* phase 5 */ tmp11 = (z11 - z13) * 1.414213562; /* 2*c4 */ z5 = (z10 + z12) * 1.847759065; /* 2*c2 */ tmp10 = z5 - z12 * 1.082392200; /* 2*(c2-c6) */ tmp12 = z5 - z10 * 2.613125930; /* 2*(c2+c6) */ tmp6 = tmp12 - tmp7; /* phase 2 */ tmp5 = tmp11 - tmp6; tmp4 = tmp10 - tmp5; wsptr[0] = tmp0 + tmp7; wsptr[7] = tmp0 - tmp7; wsptr[1] = tmp1 + tmp6; wsptr[6] = tmp1 - tmp6; wsptr[2] = tmp2 + tmp5; wsptr[5] = tmp2 - tmp5; wsptr[3] = tmp3 + tmp4; wsptr[4] = tmp3 - tmp4; I can't make sense out of this. I removed some unrelated things like quantization, and turned 2d transformation to 1d, 8 numbers on input and 8 numbers on output. I need to read those papers. |
|||
|
|
vivik 15 May 2018, 16:43
Simplified it a bit more, and confirmed that this actually works:
Code: #include <stdio.h> int main() { float arr[8] = {0, 1, 2, 3, 3, 3, 2, 0}; printf("%f %f %f %f %f %f %f %f\n\n\n", arr[0], arr[1], arr[2], arr[3], arr[4], arr[5], arr[6], arr[7]); { float t0 = arr[0] + arr[7]; float t7 = arr[0] - arr[7]; float t1 = arr[1] + arr[6]; float t6 = arr[1] - arr[6]; float t2 = arr[2] + arr[5]; float t5 = arr[2] - arr[5]; float t3 = arr[3] + arr[4]; float t4 = arr[3] - arr[4]; /* Even part */ float t10 = t0 + t3; /* phase 2 */ float t13 = t0 - t3; float t11 = t1 + t2; float t12 = t1 - t2; arr[0] = t10 + t11; /* phase 3 */ arr[4] = t10 - t11; float z1 = (t12 + t13) * 0.707106781; /* c4 */ arr[2] = t13 + z1; /* phase 5 */ arr[6] = t13 - z1; /* Odd part */ t10 = t4 + t5; /* phase 2 */ t11 = t5 + t6; t12 = t6 + t7; /* The rotator is modified from fig 4-8 to avoid extra negations. */ float z5 = (t10 - t12) * 0.382683433; /* c6 */ float z2 = 0.541196100 * t10 + z5; /* c2-c6 */ float z4 = 1.306562965 * t12 + z5; /* c2+c6 */ float z3 = t11 * 0.707106781; /* c4 */ float z11 = t7 + z3; /* phase 5 */ float z13 = t7 - z3; arr[5] = z13 + z2; /* phase 6 */ arr[3] = z13 - z2; arr[1] = z11 + z4; arr[7] = z11 - z4; } printf("%f %f %f %f %f %f %f %f\n\n\n", arr[0], arr[1], arr[2], arr[3], arr[4], arr[5], arr[6], arr[7]); { /* Even part */ float t0 = arr[0]; float t1 = arr[2]; float t2 = arr[4]; float t3 = arr[6]; float t10 = t0 + t2; /* phase 3 */ float t11 = t0 - t2; float t13 = t1 + t3; /* phases 5-3 */ float t12 = (t1 - t3) * 1.414213562 - t13; /* 2*c4 */ t0 = t10 + t13; /* phase 2 */ t3 = t10 - t13; t1 = t11 + t12; t2 = t11 - t12; /* Odd part */ float t4 = arr[1]; float t5 = arr[3]; float t6 = arr[5]; float t7 = arr[7]; float z13 = t6 + t5; /* phase 6 */ float z10 = t6 - t5; float z11 = t4 + t7; float z12 = t4 - t7; t7 = z11 + z13; /* phase 5 */ t11 = (z11 - z13) * 1.414213562; /* 2*c4 */ float z5 = (z10 + z12) * 1.847759065; /* 2*c2 */ t10 = z5 - z12 * 1.082392200; /* 2*(c2-c6) */ t12 = z5 - z10 * 2.613125930; /* 2*(c2+c6) */ t6 = t12 - t7; /* phase 2 */ t5 = t11 - t6; t4 = t10 - t5; arr[0] = t0 + t7; arr[7] = t0 - t7; arr[1] = t1 + t6; arr[6] = t1 - t6; arr[2] = t2 + t5; arr[5] = t2 - t5; arr[3] = t3 + t4; arr[4] = t3 - t4; } printf("%f %f %f %f %f %f %f %f\n\n\n", arr[0], arr[1], arr[2], arr[3], arr[4], arr[5], arr[6], arr[7]); { arr[0] = arr[0]/8; arr[1] = arr[1]/8; arr[2] = arr[2]/8; arr[3] = arr[3]/8; arr[4] = arr[4]/8; arr[5] = arr[5]/8; arr[6] = arr[6]/8; arr[7] = arr[7]/8; } printf("%f %f %f %f %f %f %f %f\n\n\n", arr[0], arr[1], arr[2], arr[3], arr[4], arr[5], arr[6], arr[7]); getchar(); } Output is: Code: 0.000000 1.000000 2.000000 3.000000 3.000000 3.000000 2.000000 0.000000 14.000000 -2.720777 -11.656855 1.955410 -2.000000 0.873017 -0.343146 -0.107651 0.000000 8.000000 16.000000 24.000000 24.000000 24.000000 16.000000 0.000000 0.000000 1.000000 2.000000 3.000000 3.000000 3.000000 2.000000 0.000000 |
|||
|
|
vivik 16 May 2018, 06:00
Okay, I can read butterfly diagrams now. Lines are additions, lines with arrows are substractions (i guess because for substraction the direction is important, unlike for addition), boxes with a1 a2 a3 a4 a5 are multiplications by this constant number. Black and white circles don't mean anything, they probably indicate direction, doesn't matter.
I can follow most of the code, except this part in inverse dct: Code: float z5 = (z10 + z12) * 1.847759065; /* 2*c2 */ t10 = z5 - z12 * 1.082392200; /* 2*(c2-c6) */ t12 = z5 - z10 * 2.613125930; /* 2*(c2+c6) */ It looks like code comments use those weird c2 c4 c6 constants, and I know only a1 a2 a3 a4 a5. Most of those constants are just divisions, turned into multiplications, (instead of dividing by a1, they multiply by 1/a1 instead. Same result, but slightly faster). Yet this 1.082392200 constant is 1 / 0.923, and there is no such number. Code: a1 and a3 1.414213562 0.707 a2 1.8477 0.541 ????? 1.082392200 0.923 ???? it should be a4 = 1.307 a5 2.613125930 0.3826 |
|||
|
|
vivik 16 May 2018, 15:12
wait, I think I found what c2 c4 c6 mean.
https://unix4lyfe.org/dct-1d/ >For brevity, let's define: >c0 = sqrt(1/2)*sqrt(2/N) >cj = cos(pi * j / 16) * sqrt(2/N) then, let's check that 2*(c2-c6) == 1.082392200 c2 = cos(pi * 2 / 16) * sqrt(2 / 8) c6 = cos(pi * 6 / 16) * sqrt(2 / 8) well, i just typed this into google: 2 * ( (cos(pi * 2 / 16) * sqrt(2 / 8)) - (cos(pi * 6 / 16) * sqrt(2 / 8)) ) and got 0.54119610014 ...that's exactly twice as small as what I expected. How odd. I guess without sqrt(2/8) it will be exact... Hm, this is what @Siekmanski was talking about... |
|||
|
|
vivik 16 May 2018, 16:46
0.707 = 1.414 / 2
0.707 = 1 / 1.414 0.707 = c4 = cos(pi * 4 / 16) = cos(45 grad) = cos(45 degrees) = sqrt(2)/2 wow How would you prove that 1 / cos(45 degrees) = cos(45 degrees) / 2 ? |
|||
|
| Goto page 1, 2 Next < Last Thread | Next Thread > |
Forum Rules:
|